ViT applies a standard Transformer directly to images
- Split an image into patches;
- Provide the sequence of linear embeddings of these patches as an input to a Transformer.
Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion.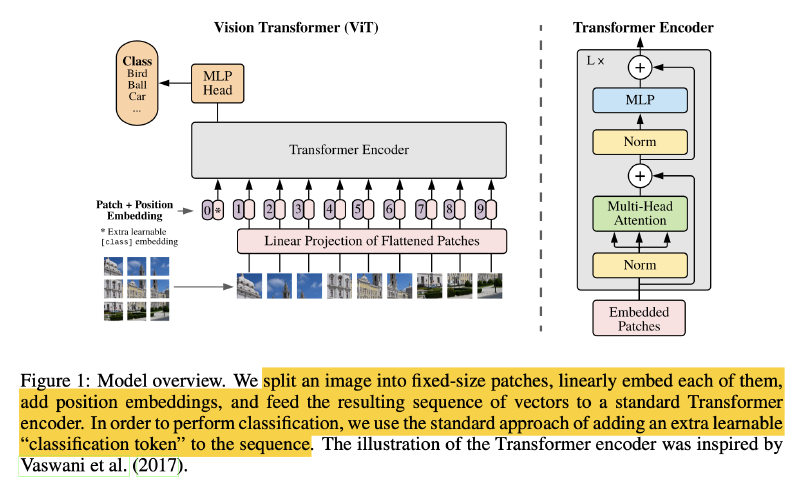
Methods
Reshape the image $x ∈ R^{H×W×C }$ into a sequence of flattened 2D patches
- $N =HW/P^2=224 \times 224/16^2=196$ is the resulting number of patches
Flatten the patches and map to $D=768$ dimensions with a trainable linear projection
- the output of this projection as the patch embeddings.
Prepend a learnable embedding to the sequence of embedded patches $\mathbf{z}^0_0$ = $\mathbf{x}_{class}$ (1x768), whose state at the output of the Transformer encoder $\mathbf{z}^L_0$ serves as the image representation $\mathbf{y}$.
Position embeddings ($E_{pos} ∈ \mathbb{R}^{(N+1)×D}$ or $\mathbb{R}^{197 \times 768}$ ) are added to the patch embeddings to retain positional information.
A classification head is attached to $\mathbf{z}_0^L$. The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time.
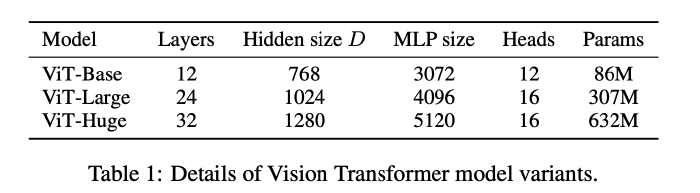
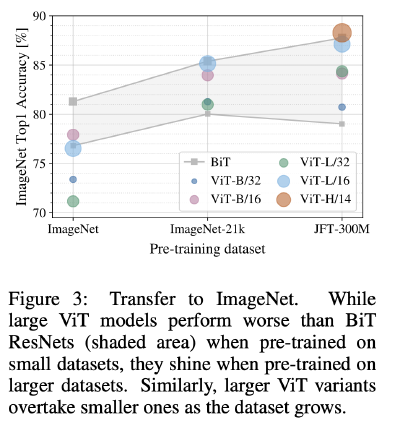
Reference: