A new ViT whose representation is computed with Shifted windows*!***
Challenge in transferring Transformer from language to vision can be explained by differences between the two modalities:
- Visual elements can vary substantially in scale (object detection)
- Much higher resolution of pixels in images (semantic segmentation) → the computational complexity of self-attention quadratic to image size.
(For dense prediction tasks like semantic segmentation, object detection, 有”多尺寸的特征”是至关重要的)
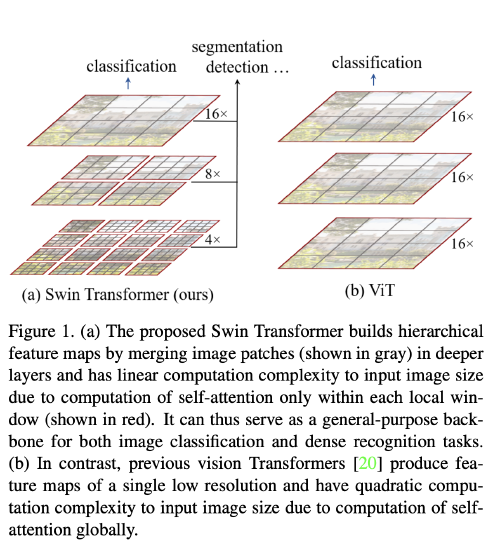
Novelty: This hierarchical architecture has the flexibility to model at various scales (via patch merging) and has linear computational complexity (via self-attention computed locally) with respect to image size.
Contribution: demonstrating the potential of Transformer-based models as vision backbones
Key Design: shift of the window partition between consecutive self-attention layers.
- Bridge the windows of the preceding layer, providing connections among them.
- Much lower latency than the sliding window method.
Archetecture:
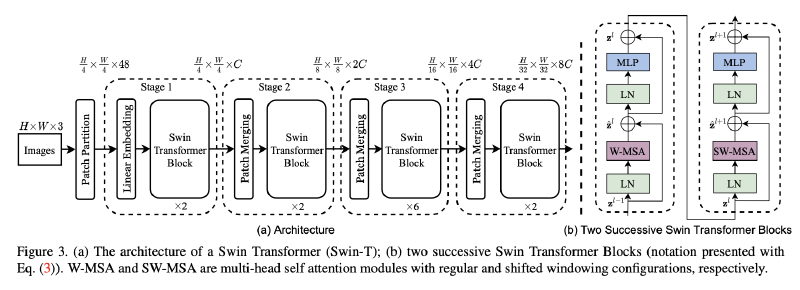
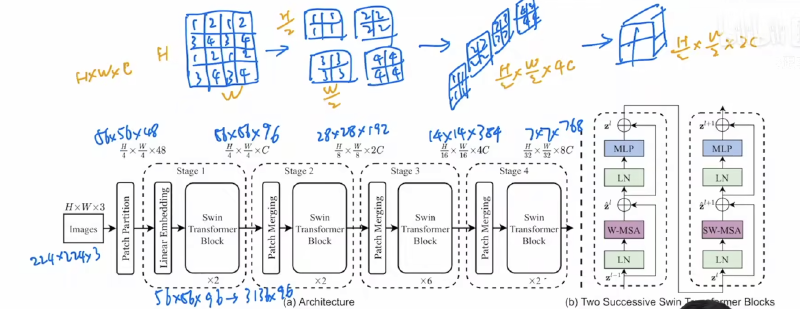
Patch Partition: splits an input image into non-overlapping 4 × 4 patches (token) by a patch splitting module, like ViT.
- Feature dimension of each patch is 4×4×3 = 48.
Stage 1:
- A linear embedding layer is applied on this raw-valued feature to project it to an arbitrary dimension (denoted as C ).
- Several Transformer blocks with modified self-attention computation (Swin Transformer blocks) are applied on these patch tokens.
Stage 2:
- To produce a hierarchical representation, the number of tokens is reduced by patch merging layers as the network gets deeper.
- Swin Transformer blocks are applied afterwards for feature transformation.
These stages jointly produce a hierarchical representation.
Swin Transformer block
- Transformer block consists of a shifted window based multi-head self attention(MSA) module, followed by a 2-layer MLP with GELU non- linearity in between. A LayerNorm (LN) layer is applied before each MSA module and each MLP, and a residual connection is applied after each module
Shifted Window based Self-Attention
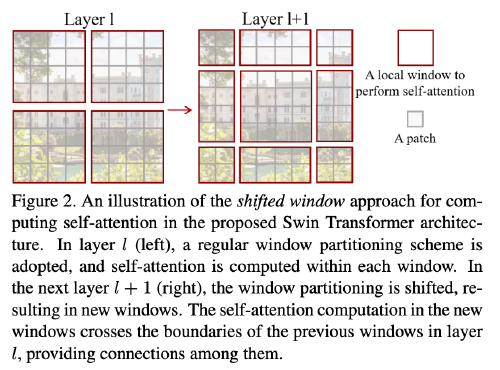
- Self-attention in non-overlapped windows: Compute self-attention within local windows. The windows are arranged to evenly partition the image in a non-overlapping manner.
- Shifted window partitioning in successive blocks: To introduce cross-window connections, a shifted window partitioning approach which alternates between two partitioning configurations in consecutive Swin Transformer blocks.
With the shifted window partitioning approach, consecutive Swin Transformer blocks are computed as


Efficient batch computation for shifted configuration
Issue: Shifted window partitioning will result in more windows.
Solution: batch computation approach by cyclic-shifting toward the top-left direction.
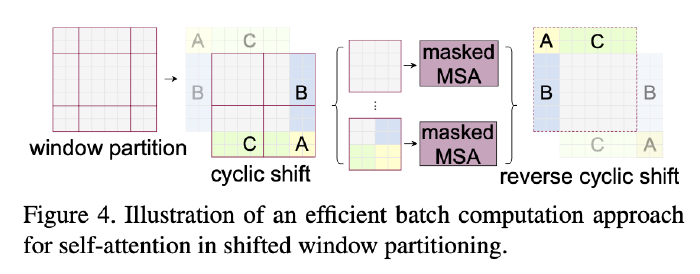
- After this shift, a batched window may be composed of several sub-windows that are not adjacent in the feature map, so a masking mechanism is employed to limit self-attention computation to within each sub-window.
- With the cyclic-shift, the number of batched windows remains the same as that of regular window partitioning, and thus is also efficient.