This week, I want to resume sharing my paper reading notes. The paper I read this weenkend is “From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge” by Li, Dawei, et al. (2024), as it’s particularly relevant to my current work. For the first time, I tried out Google’s NotebookLM to help with my note-taking –– It’s game-changing! BTW, my attention has recently shifted from multimodality in the Search domain to LLMs/chatbots. Hopefully, I can find more time to keep reading, learning, and, of course, sharing.
More resources about their line of work:
- LLM-as-a-judge: https://llm-as-a-judge.github.io/
- Paper list about LLM-as-a-judge: https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge
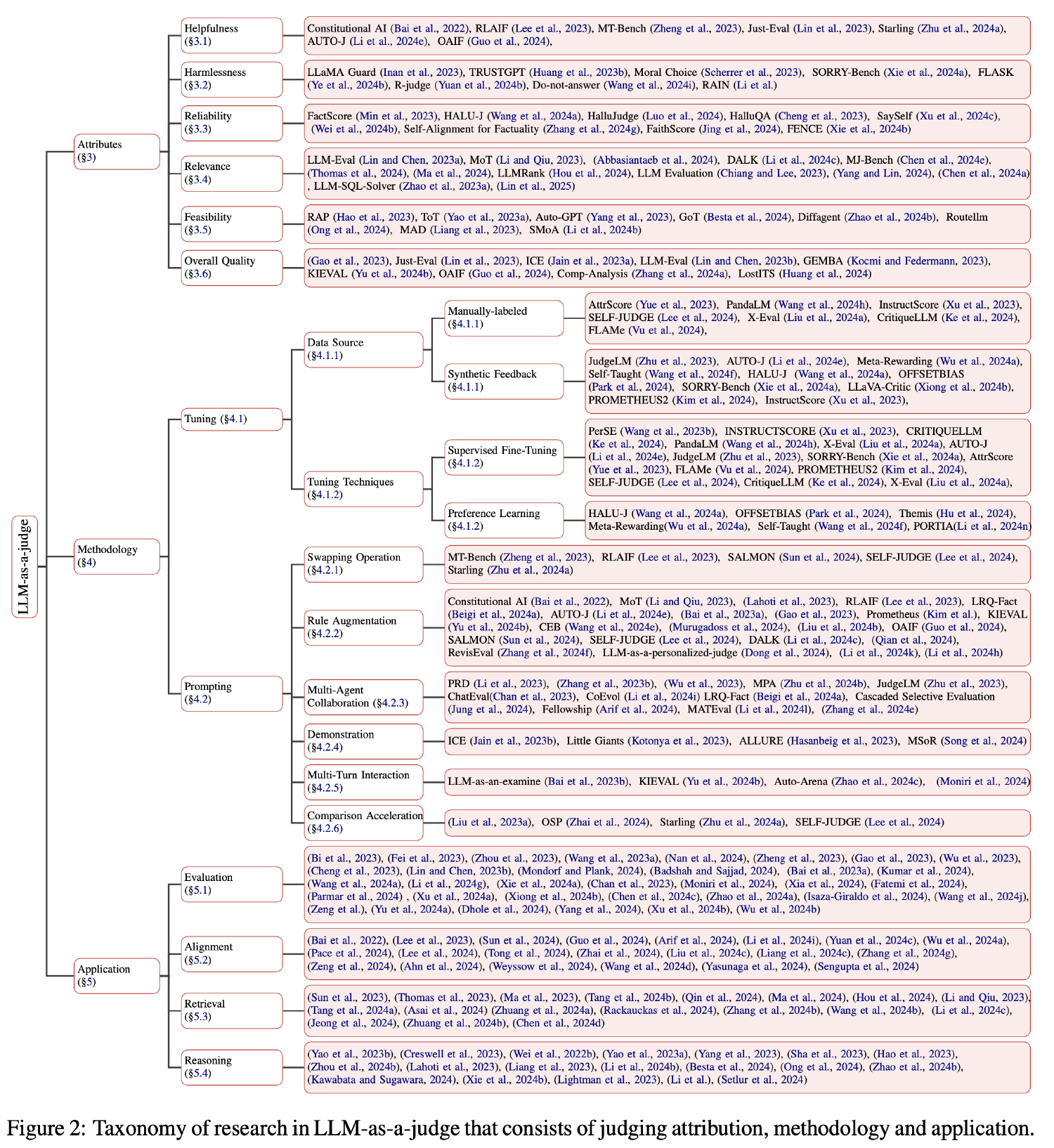
Attributes of Judgment
- Helpfulness: LLMs can be used to label helpfulness, generate or evaluate alignment data, and serve as general-purpose helpfulness evaluators.
- RLAIF (Lee et al., 2023): helpfulness feedback from AI, i.e., LLMs are comparable to human feed- back
- Starling (Zhu et al., 2024a): successful LLMs with superior per- formance that have been fine-tuned with AI feed- back data thus demonstrating the feasibility and usefulness of this method.
- OAIF (Guo et al., 2024): Uses an LLM in an online manner to get preferences for the direct alignment of another LLM.
- MT-Bench (Zheng et al., 2023), Just-Eval (Lin et al., 2023): Frameworks using LLMs as evaluators for assessing helpfulness of candidate responses.
- Harmlessness: LLMs can be used to assess harmlessness in text data for content moderation and synthetic dataset creation.
- LLaMA Guard (Inan et al., 2023): State-of-the-art LLMs are capable of being used effectively for content moderation, either off the shelf when guided with some policy guidelines, or when fine-tuned on safe/unsafe data.
- SORRY-Bench (Xie et al., 2024a): a comprehensive comparison of several LLMs on a benchmark of LLM safety refusals and find small LLMs are effective safety judges when used in fine-tuned settings.
- Constitutional AI (Bai et al., 2022): use principles to guide LLMs to make harmlessness evaluations for alignment purposes.
- Reliability: LLMs can generate factual and faithful content while also expressing uncertainty or acknowledging gaps in knowledge about certain topics.
- FactScore (Min et al., 2023): a fine-grained method for evaluating the factuality of long-form generation by first splitting content into atomic-level sentences and retrieving relevant corpus from Wikipedia to assess their factuality.
- HALU-J (Wang et al., 2024a): a critique-based hallucination judge that enhances factuality assessment by selecting relevant evidence and providing detailed critiques.
- SaySelf (Xu et al., 2024c): For uncertainty judgment, Xu et al. (2024c) present SaySelf, a novel training framework that teaches LLMs to express more fine-grained confidence estimates with self-consistency prompting and group-based calibration training.
- HalluQA (Cheng et al., 2023): design an automated evaluation method us- ing GPT-4 to judge whether a model’s output is hallucinated.
- HalluJudge (Luo et al., 2024): collect a large-scale benchmark for automatic dialogue-level hallucination evaluation, and instroduce a specialized judge language model for evaluating hallucinations at the di- alogue level.
- (Wei et al., 2024b): propose equipping judge LLMs with a Google search API to enable more flexible and efficient factuality assessments.
- FaithScore (Jing et al., 2024): expand this fine- grained reliability evaluation to the multimodal area.
- Self-Alignment for Factuality (Zhang et al., 2024g): creating a synthetic alignment dataset, which involves evaluating and filtering each generated sample us- ing claim extraction and self-judging techniques.
- FENCE (Xie et al., 2024b): train an external critique-based LLM as the judge to provide claim-level claim- level factuality feedback in the generation stage to improve response factuality.
- Relevance: LLMs can be applied to judge relevance in tasks such as document ranking, information retrieval, and knowledge base question answering, to be a more fine- grained and effective manner.
- LLM-Eval (Lin and Chen, 2023a): replace the expensive and time-consuming human annotation with LLM judgment in relevance assessment, providing conversation context and generated response for the judge LLM to evaluate.
- MoT (Li and Qiu, 2023): In retrieval-augmented generation (RAG) scenarios, utilize LLMs to determine which historical memory is most relevant for solving the current problem.
- DALK (Li et al., 2024c): propose to adopt LLM as a re-ranker to judge and filter out noisy and irrelevant knowledge in a sub-knowledge graph.
- (Abbasiantaeb et al., 2024): apply LLM-as-a-judge in conversation search, collaborat- ing with human annotators to address issues related to incomplete relevance judgments.
- MJ-Bench (Chen et al., 2024e): employ the multimodal reward model to assess the relevance in text-to-image generation.
- LLM-SQL-Solver (Zhao et al., 2023a): leverage LLM to determine SQL equivalence.
- Feasibility: LLMs can judge the feasibility of actions or steps in complex reasoning pipelines, aiding in planning, decision-making, and problem-solving. (agentic LLMs)
- ToT (Yao et al., 2023a): adopting the LLM as the state evaluator for potential step searching in their proposed tree-of-thought (ToT) framework.
- (Liang et al., 2023) and (Li et al., 2024b): In multi-agent collaboration systems, both Liang et al. (2023) and Li et al. (2024b) propose to leverage the judge LLM to select the most feasible and reasonable solutions among multiple candidates’ responses.
- RAP (Hao et al., 2023): first propose to prompt the LLM to do self-evaluation and generate feasibility judgment as a reward sig- nal to perform Monte Carlo Tree Search (MCTS).
- GoT (Besta et al., 2024): replace the tree struc- tures used in previous studies with graph structures and employ the LLM to assign a score to each thought based on its feasibility or correctness.
- MAD (Liang et al., 2023) & SMoA (Li et al., 2024b): leverage the judge LLM to select the most feasible and rea- sonable solutions among multiple candidates’ responses.
- Adopt the judge LLMs to perform feasibility assessment in API selection (Diffagent, Zhao et al., 2024b), tool using (Auto-GPT, Yang et al., 2023) and LLM routing (Routellm, Ong et al., 2024).
- Overall Quality: While LLMs can provide fine-grained assessments on various aspects, they can also give an overall quality judgment, useful for comparison and ranking purposes.
- (Just-Eval, Lin et al., 2023; LLM-Eval, Lin and Chen, 2023b): obtain this overall score by calculating the average of the aspect-specific scores.
- (KIEVAL, Yu et al., 2024b; OAIF, Guo et al., 2024; Comp-Analysis, Zhang et al., 2024a): present assessment results for each attribute and prompt the LLM judge to generate an overall quality judgment.
Methodology
Tuning: Techniques for improving the judging abilities of a general LLM.
Data Source:
- Manually-labeled data: To train an LLM judge using human-like criteria, collecting manually-labeled data and their corresponding judgments.
- AttrScore (Yue et al., 2023): first propose the evaluation of attribution and fine-tune judge LLMs with data from related tasks such as question answering, fact-checking, natural language inference, and sum- marization.
- PandaLM (Wang et al., 2024h): Collect diverse human-annotated test data, where all contexts are human-generated and labels are aligned with human preferences.
- InstructScore (Xu et al., 2023): InstructScore (an explainable text generation evaluation metric) and curates the MetricInstruct dataset, which covers six text generation tasks and 23 datasets.
- SELF-JUDGE (Lee et al., 2024): To enhance the policy’s judging ability in alignment data synthesis, this approach augments the supervised fine-tuning dataset with a pairwise judgment task, where the instruc- tion is to select the chosen response from a set of options.
- X-Eval (Liu et al., 2024a): collect ASPECTINSTRUCT, the first instruction-tuning dataset designed for multi-aspect NLG evaluation.
- CritiqueLLM (Ke et al., 2024): first prompts GPT-4 to produce the feedback and manually check its generated texts for each user query, revising them if necessary to improve the quality.
- FLAMe (Vu et al., 2024): ses a large and diverse collection of over 100 quality assessment tasks, including more than 5 million human judgments, curated from publicly available data.
- Synthetic Feedback: Use synthetic data as a data source for tuning judge LLMs, often generated by LLMs themselves.
- JudgeLM (Zhu et al., 2023): propose a comprehensive, large-scale, high-quality dataset containing task seeds, LLMs-generated answers, and GPT-4-generated judgments for fine-tuning high-performance judges.
- AUTO-J (Li et al., 2024e): Uses GPT-4 to synthesize pairwise and pointwise data to train a generative judge LLM
- Meta-Rewarding (Wu et al., 2024a): Constructs pairwise feedback for judgment enhancement by prompting policy LLMs to evaluate their own judgments.
- Self-Taught (Wang et al., 2024f): prompt the LLM to generate a “noisy” version of the original instruction and use the corresponding response to this corrupted instruction as the inferior response.
- HALU-J (Wang et al., 2024a): GPT-4-Turbo is used to generate multiple pieces of evidence based on original evidence, categorized into different relevance levels, to train a hallucination judgment LLM.
- OFFSETBIAS (Park et al., 2024): a pairwise preference dataset that leverages GPT-4 to generate bad, off-topic and erroneous responses and perform difficulty filtering.
- SORRY-Bench (Xie et al., 2024a): Uses GPT-4 as a classifier to assign data points to safety categories for training an automated evaluator.
- LLaVA-Critic (Xiong et al., 2024b): adopt GPT-4o to generate reasons behind given scores or preference judgments for training data construc- tion.
- PROMETHEUS2 (Kim et al., 2024): Uses GPT-4 to augment the preference learning dataset with human evaluation criteria and verbal feedback.
- InstructScore (Xu et al., 2023): By harnessing both explicit human instruction and the implicit knowledge of GPT- 4, Xu et al. (2023) fine-tune a judge LLM based on LLaMA, producing both a score for generated text and a human-readable diagnostic report.
Tuning Techniques
- Supervised Fine-Tuning (SFT): the most commonly used approach to facilitate the judge LLMs to learn from pairwise or pointwise judgment data.
- (FLAMe): Vu et al. (2024) propose a supervised multitask training to tune their Foundational Large Autorater Models (FLAMe) across multiple mixed datasets of various tasks.
- (PROMETHEUS2): To equip the judge LLM with both pairwise and pointwise judging capabilities, Kim et al. (2024) novelly propose joint training and weight merging approaches during the tuning stage and find the latter does not improve evaluation performances in the majority of cases.
- (SELF-JUDGE): To obtain a judge model that can not only generate responses but also compare pairwise preferences, Lee et al. (2024) devise Judge-augmented Supervised Fine-tuning (JSFT) with an augmented preference learning dataset.
- (CritiqueLLM): During the training phase, Ke et al. (2024) enhance their model by adding simplified prompts to distinguish different parts of inputs and augment pairwise training data by swapping the order of two generated texts and exchanging the corresponding content in critiques.
- (INSTRUCTSCORE): Xu et al. (2023) further fine-tune their INSTRUCTSCORE model on self-generated outputs to optimize feedback scores, resulting in diagnostic reports that are better aligned with human judgment.
- (X-Eval): Liu et al. (2024a) also propose a two-stage supervised fine-tuning approach, first applying vanilla instruction tuning to equip the model with the ability to follow instructions for diverse evaluations. They then perform further tuning with auxiliary aspects to enrich the training process, incorporating an additional instruction-tuning stage to leverage potential connections to the target evaluation aspect.
- Preference Learning: Aligns with judgment and evaluation tasks by training the LLM to learn from comparisons and rankings.
- (HALU-J): To enhance the quality of judg- ment provided by HALU-J, Wang et al. (2024a) fur- ther tune it with Directed Preference Optimization (DPO) (Rafailov et al., 2023) after the SFT stage under the multiple-evidence setting.
- (OFFSETBIAS): apply DPO with synthetic “bad” re- sponses that contain critical errors but exhibit stylis- tic qualities favored by judge models, helping to mitigate bias in the judge LLMs.
- (Meta-Rewarding): leverages the policy LLMs to judge the quality of their own judgment and produce pairwise signals for enhanc- ing the LLMs’ judging capability.
- (Self-Taught): propose self-taught evaluators that use corrupted instruc- tions to generate suboptimal responses as inferior examples for preference learning.
- (Themis): an LLM dedicated to NLG evaluation, which has been trained with designed multi-perspective consistency verification and rating-oriented preference alignment methods.
- (PORTIA): an alignment-based approach designed to mimic human comparison behavior to calibrate position bias in an effective manner.
- Manually-labeled data: To train an LLM judge using human-like criteria, collecting manually-labeled data and their corresponding judgments.
Prompting: Strategies for improving judgment accuracy and mitigating bias at the inference stage.
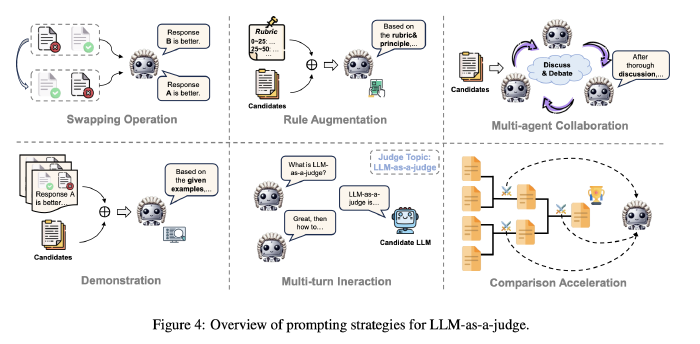
Swapping Operation: mitigate positional bias in LLM judgments.
LLM- based judges are sensitive to the positions of candidates, and the quality ranking of candidate responses can be easily manipulated by merely alter- ing their order in the context
- Swapping Operation (Zheng et al., 2023): The judge LLM is invoked twice with swapped candidate order; In evaluations, if results are inconsistent, it’s labeled a “tie”, indicating that the LLM is unable to confidently distinguish the quality of the candidates.
- (Lee et al., 2023; Sun et al., 2024; Lee et al., 2024) incorporated swapping operations in self-alignment to obtain more accurate pairwise feedback from the judge LLM.
- Starling (Zhu et al., 2024a): Proposed a CoT-like prompting technique to mitigate the positional bias by asking the model to first provide all pairwise ranking, then summarize with a ranking list.
Rule Augmentation: Involves embedding principles, references, or evaluation rubrics directly to the LLM judge’s prompt.
This approach is commonly employed in LLM-based evaluations, where judge LLMs are guided to assess specific aspects (Li et al., 2024e; Bai et al., 2023a; Yu et al., 2024b; Qian et al., 2024) and provided with detailed rubrics (Gao et al., 2023; Kim et al.; Wang et al., 2024e; Murugadoss et al., 2024; Li et al., 2024k,h) to ensure a fair comparison.
- (Liu et al., 2024b): the judge LLM is prompted to generate its own scoring criteria through in-context learning on a set of few-shot examples.
- Constitutional AI (Bai et al., 2022): In alignment with LLM-as-a-judge, Bai et al. (2022) first propose to introduce a list of principles (e.g., helpfulness, harmlessness, honesty) for the judge LLM to compare the two candidates more precisely and directionally.
- (Lee et al., 2023, 2024; Guo et al., 2024; Sun et al., 2024; Beigi et al., 2024a): Following them, subsequent works enhance this principle-driven prompting by incorporating more detailed explanations for each aspect of the principle or rubric.
- MoT (Li and Qiu, 2023), DALK (Li et al., 2024c): propose to prompt LLMs to retrieve appropriate demonstrations/ knowledge triples based on the candidates’ helpfulness in solving specific problems.
- (Lahoti et al., 2023): To obtain diverse responses from LLMs, Lahoti et al. (2023) prompt multiple LLMs to judge the diversity of each candidate and select the most diverse one for further polishing.
- RevisEval (Zhang et al., 2024f): leverages the self-correction capabilities of LLMs to adaptively revise the response, then treat the revised text as the principles for the subsequent evaluation.
- (Dong et al., 2024): investigate the reliability of LLM-as-a-personalized-judge, providing persona as a part of principles for LLMs to make personalized judgments.
Multi-agent Collaboration: Using multiple LLM judges to address bias limitations from single LLM judges.
- PRD (Li et al., 2023): Introduced the Peer Rank (PR) algorithm to address the limitations of single LLM judges, which are prone to various biases.
- (Zhang et al., 2023b): Mixture-of-Agent architectures.
- (Wu et al., 2023): Role play for multi-agent LLMs.
- ChatEval (Chan et al., 2023), (Zhang et al., 2024e): Debating techniques for multi-agent LLMs.
- MPA (Zhu et al., 2024b): Voting mechanisms in multi-agent LLM systems.
- Cascaded Selective Evaluation (Jung et al., 2024): less expensive models serve as initial judges, escalat- ing to stronger models only when necessary
- Fellowship (Arif et al., 2024): apply multi-agent collaboration for alignment data syn- thesis, leveraging multiple LLM judges to refine responses.
- MATEval (Li et al., 2024l): all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative dis- cussion methods, integrating multiple agents’ inter- actions to evaluate open-ended text.
- JudgeLM (Zhu et al., 2023): Using multiple LLMs as judges to refine responses or provide more accurate feedback.
- CoEvol (Li et al., 2024i): leveraging multiple LLM judges to provide more accurate pairwise feedback
Demonstration: Provides concrete examples for the LLMs to follow using in-context learning, aiming to improve evaluation effectiveness and robustness.
- ICE (Jain et al., 2023b): First explores the effectiveness of LLMs as multi-dimensional evaluators using in-context learning.
- Little Giants (Kotonya et al., 2023): conduct systematic experiments with various prompting techniques, including standard prompting, prompts informed by annotator instructions, and chain-of- thought prompting, combining these methods with zero-shot and one-shot learning to maximize eval- uation effectiveness.
- ALLURE (Hasanbeig et al., 2023): Iteratively incorporates demonstrations of significant deviations to enhance the evaluator’s robustness.
- MSoR (Song et al., 2024): Uses two many-shot in-context learning (ICL) templates to mitigate biases.
Multi-Turn Interaction: Dynamic interaction between the judge LLM and candidate models to facilitate a comprehensive evaluation.
In evaluation, a single response may not provide enough information for an LLM judge to thor- oughly and fairly assess each candidate’s perfor- mance. Typically, the process begins with an initial query or topic, followed by dynamically interacting between the judge LLM and candidate models.
- LLM-as-an-examine (Bai et al., 2023b): Uses multi-round interactions where the evaluator poses increasingly complex questions based on prior answers.
- KIEVAL (Yu et al., 2024b): Incorporates an LLM-powered interactor to enable dynamic and contamination-resilient assessments.
- Auto-Arena (Zhao et al., 2024c): Facilitates multi-round peer battle around a query between two LLMs.
- (Moniri et al., 2024): Proposed an automated benchmarking system where LLMs debate, with the final assessment carried out by another LLM judge.
Comparison Acceleration: Techniques to reduce the time complexity of pairwise comparisons, especially when ranking multiple candidates.
- OSP (Zhai et al., 2024): Uses a ranked pairing method where candidates are first compared to a baseline response to determine rank.
- Starling (Zhu et al., 2024a): Proposed a CoT-like prompting technique to mitigate the positional bias by forcing the model to provide all pairwise ranking first, then summarize these pairwise rankings with a list.
- SELF-JUDGE (Lee et al., 2024): Employs a tournament-based approach for rejection sampling during inference.
Application
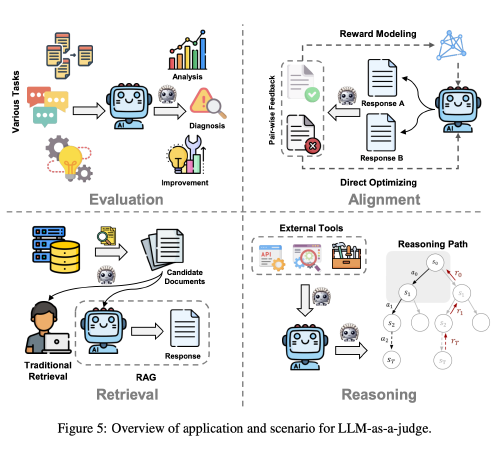
- Evaluation: Traditional NLP evaluation relies on predefined metrics, such as BLEU, ROUGH, and BERTScore, to assess machine-generated text quality. However, these methods often fall short in capturing nuanced semantic attributes. LLM-as-a-judge enables human-like qual- itative evaluations rather than simple quantitative comparisons of how well machine-generated out- puts match the ground truth.
- Open-Ended Generation Tasks: tasks where multiple safe, accurate, and contextually relevant responses exist, such as dialogue generation, summarization, and creative writing.
- (Zheng et al., 2023): Found that LLMs like GPT-4 perform comparably to humans when judging open-ended text generation.
- (Gao et al., 2023): Used ChatGPT for human-like summarization evaluation.
- (Wu et al., 2023): Proposed a comparison-based framework where LLMs act as judges with multiple role-playing to evaluate summarization quality in a specific dimension and generate its evaluations.
- (Cheng et al., 2023; Zhang et al., 2024d): Introduced an evaluation method using GPT-4 to judge the presence of hallucinations in generated outputs.
- (Wang et al., 2024a): Proposed a critique-based judging system to evaluate hallucinations with evidence selection and detailed critiques.
- (Li et al., 2024g): Introduced MD-Judge and MCQ-Judge for evaluating safety-related QA pairs, focusing on queries designed to elicit unsafe responses.
- (Xie et al., 2024a): Conducted a meta-evaluation to assess LLM refusal tendencies in response to potentially unsafe queries.
- (Yu et al., 2024a): Introduced an LLM-based answer extractor to pinpoint critical answer parts from open-ended generation.
- (An et al., 2023): Proposed L-Eval, an LLM-as-a-judge framework for standardized evaluation of long-context language models.
- (Moniri et al.,2024): propose an automated debate framework that evaluates LLMs not only on domain knowledge but also on their abilities in problem definition and inconsistency recognition.
- Reasoning Tasks: LLM reasoning capabilities can be assessed by evaluating their intermediate thinking processes and final answers.
- (Xia et al., 2024): Introduced an automatic framework using a judge LLM to assess the quality of reasoning steps in mathematical problem-solving.
- (Fatemi et al., 2024): Built synthetic datasets to evaluate LLMs’ temporal reasoning abilities in various scenarios.
- (Wang et al.,2023a): design a debate-style framework to evaluate LLMs’ reasoning capability. Given a specific question, the LLM and the user adopt opposing positions and discuss the topic to reach a correct decision.
- (Nan et al., 2024): develop a multi-agent evaluation framework that simulates the academic peer-review process, offering a more nuanced understanding of LLMs’ reasoning capabilities in data-driven tasks.
- Emerging Tasks:
- Social intelligence: models are presented with complex social scenarios requiring the understanding of cultural values, ethical principles, and potential social impacts.
- Large Multimodality Models: Xiong et al. (2024b) and Chen et al. (2024c) find that evaluations performed by LLMs-as-judges align more closely with human preferences than those conducted by LVLM-as-judges.
- More…
- Open-Ended Generation Tasks: tasks where multiple safe, accurate, and contextually relevant responses exist, such as dialogue generation, summarization, and creative writing.
- Alignment: Alignment tuning aligns LLMs with human preferences and values. A key part of this process is the collection of high-quality, pair- wise feedback from humans, which is essential for reward modeling (Schulman et al., 2017) or direct preference learning (Rafailov et al., 2023). Using LLM-as-a-judge to automate this feedback is gaining interest.
Larger Models as Judges: leverage the feedback from larger, more powerful LLMs to guide smaller, less capable models.
- (Bai et al., 2022): First using AI feedback for building harmless AI assistants. They train the reward model using synthetic preference data based on the preference of a pre- trained language model.
- (Lee et al., 2023): Showed that the RLAIF method can achieve comparable performance with RLHF even when the LLM judge is not strong enough. Proposed DIRECT-RLAIF to use an off-the-shelf LLM judge to mitigate reward staleness.
- (Sun et al., 2024): To avoid reward hacking in alignment, Sun et al. (2024) devise an instructable reward model trained on synthetic preference data. It enables humans to perform RL-time interventions to better align the target policy with human values.
- (Guo et al., 2024): Introduced online AI feedback (OAIF), directly using preference signals from an annotation model to train the target model.
- (Arif et al., 2024; Sengupta et al., 2024): Constructed a synthetic preference optimization dataset using multi-agent workflows and adopt LLMs as judges with diverse prompting strategies and pipelines.
- (Li et al., 2024i): Employed multiple LLMs to debate, iteratively improving response quality, while creating a judge LLM to select preferred responses for enhanced instruction tuning.
- BPO (Wang et al., 2024d): Use GPT-4 as the judge and constructing synthetic pairwise feedback for knowledge depth and breadth balance in the alignment process.
Self-Judging: Leveraging the preference signals from the same LLM for self-improvement.
- (Yuan et al., 2024c): Introduced the concept of a self-rewarding LLM, where pairwise data is con- structed by having the LLM itself serve as the judge
- Meta-rewarding (Wu et al., 2024a): judges an LLM’s judgment and uses the feedback to improve its judging skills.
Their LLM-as-a-meta-judge approach significantly enhances the model’s capacity to evaluate and follow instructions.
- West-of-N (Pace et al., 2024): Combining Best-of-N and Worst-of-N sampling strategies to improve synthetic data quality.
- (Lee et al., 2024): Developed Judge-augmented Supervised Fine-tuning (JSFT) to train a single model as both policy and judge, also proposing Self-Rejection by Tournament to select the best response in the inference time.
- (Tong et al., 2024): Used LLM-as-a-judge for self-filtering to ensure quality in synthetic data pairs for reasoning alignment tasks.
- (Zhai et al., 2024): propose a ranked pairing method for self-preferring language models, which accelerates the compari- son process by measuring the strength of each re- sponse against a baseline.
- (Liu et al., 2024c): Introduced meta-ranking, enabling weaker LLMs to act as reliable judges, also applying it in post-SFT training with Kahneman-Tversky Optimization (KTO) for improved alignment.
- I-SHEEP(Liang et al., 2024c): Using LLM-as-a-judge to score synthetic responses and select high-quality pairs for subsequent training.
- (Yasunaga et al., 2024): Proposed a combination of LLM-as-a-judge and data synthesis to build human-aligned LLMs with a few annotations.
- (Zhang et al., 2024g): Employed a self-evaluation mechanism for judging factuality by generating question-answer pairs, using these to fine-tune the model for better factuality.
- (Ahn et al., 2024): Proposed iterative self-retrospective judgment (i-SRT) for multimodal models, using self-reflection to improve response generation and preference modeling.
- Retrieval: In traditional retrieval, LLMs improve ranking by ordering documents by relevance. In RAG, LLMs generate content by leveraging retrieved information, supporting applications that require complex knowledge integration.
- Traditional Retrieval
- (Sun et al., 2023): Explored LLMs for relevance ranking using a permutation-based approach to rank passages by relevance, instructing LLMs to output ordered permutations of passages, thus enhancing ranking precision.
- (Zhuang et al., 2024a): Embedded fine-grained relevance labels within prompts, enabling LLMs to distinguish subtle relevance variations.
- LRL (Ma et al., 2023): Introduced the Listwise Reranker with a Large Language Model (LRL) to reorder document identifiers directly without task-specific training.
- (Zhuang et al., 2024b): Developed a Setwise prompting strategy for zero-shot ranking, streamlining ranking operations and enhancing efficiency.
- (Tang et al., 2024b): Proposed permutation self-consistency to average rankings across multiple list orders to yield order-independent rankings, reducing positional bias.
- PRP (Qin et al., 2024): Proposed Pairwise Ranking Prompting (PRP) with medium-sized LLMs as a cost-effective alternative to larger models.
- (Hou et al., 2024): Examined LLMs for ranking items in recommender systems by framing recommendations as conditional ranking tasks, using specialized prompting to correct biases. This framework factors in user interaction histo- ries alongside candidate items, addressing LLMs’ known biases, such as tendencies to favor popular or top-positioned items.
- (Thomas et al., 2023): Found that LLMs performed comparably to human labelers in predicting searcher preferences.
- Retrieval-Augmented Generation (RAG)
- (Chen et al., 2024d): Found that recent developments in RAG allow LLMs to self-evaluate and improve without annotated datasets or parameter adjustments.
- MoT (Li and Qiu, 2023): Introduced the Memory-of-Thought (MoT) framework, a self-reflective model that stores high-confidence reasoning as memory for later retrieval and relevance judgment.
- Self-Retrieval (Tang et al., 2024a): utilizing natural language indexing to internalize the corpus, turning retrieval into a document generation and self-assessment process, achieving a fully end- to-end IR workflow within one model.
- SELF-RAG (Asai et al., 2024): Self- Reflective Retrieval-Augmented Generation, which enhances response quality through retrieval and self-reflection, using “reflection tokens” to guide adaptive responses, allowing the model to dynamically judge and adjust its responses based on task-specific requirements.
- RAGElo (Rackauckas et al., 2024): an LLM-based evaluation framework that generates synthetic queries from actual user interactions and domain-specific documents. Within this framework, LLMs function as judges, evalu ating retrieved documents and ranking RAG agent variants via RAGElo, an Elo-based automated competition. This structure offers a scalable solution for quality control in QA systems.
- (Zhang et al., 2024b): Showed that LLMs can distinguish between relevance and utility in open-domain QA, enabling more nuanced and contextually relevant responses.
- BIORAG (Wang et al., 2024b): an advanced RAG framework that enhances vector retrieval with hierarchical knowledge structures. Adopts a self- aware evaluated retriever to continuously judge the adequacy and relevance of the information it has collected, thus improving the accuracy of the retrieved document.
- Traditional Retrieval
- Reasoning: LLM reasoning ability is key to solving complex problems. LLM-as-a-judge is being used to improve how LLMs select reasoning paths and utilize external tools.
- Reasoning Path Selection: Addresses the challenge of selecting a reliable reasoning path or trajectory for the LLM to follow.
- REPS (Kawabata and Sugawara, 2024): Rationale Enhancement through Pairwise Selection, using LLMs to select valid rationales via pairwise self-evaluation and training a verifier based on these data.
- (Lahoti et al., 2023): Found that LLMs can identify aspects where responses lack diversity, improving reasoning through critique selection and aggregation.
- MAD (Liang et al., 2023): Multi-agent debating, where a judge LLM selects the most reasonable response from multiple agents to facilitate debating and discussion among multiple agents.
- (Li et al., 2024b): Introduced judge LLMs in layer-based multi-agent collaboration for selecting high-quality and reasonable response and thus enhancing the whole system’s token utilizing efficiency.
- (Creswell et al., 2023): decompose the reasoning process into Se- lection and Inference. In the selection step, they leverage the LLM itself to judge and evaluate each potential reasoning trace, selecting the appropri- ate one for the following inference step
- Kwai-STaR (Xie et al., 2024b): Transformed LLMs into state-transition reasoners to select the best reasoning state for mathematical problem-solving.
- (Lightman et al., 2023): Used an LLM as a process reward model (PRM) for inference-time supervision and best-of-N sampling during reasoning.
- (Setlur et al., 2024): Proposed process advantage verifiers (PAVs) that generate rewards based on the changes in the likelihood of produc- ing correct responses in the future.
- (Hao et al., 2023): Employed LLMs as a world model to simulate the state of the en- vironment and perform Monte Carlo Tree Search (MCTS) to improve performance on tasks requiring deliberate path selection.
- (Besta et al., 2024): Modeled LLM thoughts as vertices in a graph, enabling judgment of coherence and logical reasoning for each state.
- ToT (Yao et al., 2023a): Tree-of-Thoughts (ToT), whereeach thought serves as an intermediate step toward problem-solving. It de- composes reasoning into steps, self-evaluates and judges progress at each state, and uses search al- gorithms with LMs to judge thought paths through lookahead and backtracking.
- Reasoning with External Tools: Involves using LLMs to interact with and utilize external tools to enhance their reasoning capabilities.
- (Yao et al., 2023b): first propose to use LLMs in an interleaved manner to generate reasoning traces and task-specific actions. Reasoning traces help the model to judge and update action plans, while actions enable it to interact with external sources.
- Auto-GPT (Yang et al., 2023): utilizes external tools to improve planning performance by having the LLM judge which tools to use.
- (Sha et al., 2023): Explored LLMs for decision-making in complex autonomous driving scenarios.
- (Zhou et al., 2024b): utilize a self- discovery process where LLMs perform judgment based on the given query and select the most feasible reasoning structure for the following inference stage.
- RouteLLM (Ong et al., 2024): uses an LLM as a router that can dynamically choose between a stronger or weaker LLM during the judging process, aiming to bal- ance the cost and response quality.
- DiffAgent (Zhao et al., 2024b): employs an LLM to select text-to-image APIs based on user prompts.
- Reasoning Path Selection: Addresses the challenge of selecting a reliable reasoning path or trajectory for the LLM to follow.
Benchmark: Judging LLM-as-a-judge
- General performance: benchmarks aim to evaluate how well LLMs do across a variety of tasks by measuring agreement with human judgments, accuracy, and correlation.
- MT-Bench and Chatbot Arena (Zheng et al., 2023): assess conversational settings using metrics such as consistency, bias, and error. These benchmarks further explore specific biases, including position bias, verbosity, and self-enhancement tendencies.
- JUDGE-BENCH (Tan et al., 2024a), DHP (Wang et al., 2024g), RewardBench (Lambert et al., 2024) and SOS-BENCH (Penfever et al., 2024): operate at larger scales, utilizing metrics like Cohen’s kappa, Discernment Score, and normalized accuracy to benchmark general LLM performance.
- LLM-judge-eval (Wei et al., 2024a): evaluates tasks such as summarization and alignment with additional metrics like flipping noise and length bias.
- Bias Quantification: ensuring fairness and reliability
- EVALBIAS-BENCH (Wang et al., 2024c) and CALM (Ye et al., 2024a): focus explicitly on quantifying biases, including those emerging from alignment and robustness under adversarial conditions**.**
- Shi et al. (2024a): Evaluates metrics such as position bias and percent agreement in question-answering tasks.
- Challenging Task Performance
- Arena-Hard Auto (Li et al., 2024j) and JudgeBench (Tan et al., 2024a): select harder questions based on LLMs’ performance for conversational QA and various reasoning tasks, respectively.
- CALM (Ye et al., 2024a): Explores alignment and challenging scenarios using metrics like separability, agreement, and hacked accuracy to evaluate performance in manually identified hard datasets.
- Domain-Specific Performance
- Raju et al. (2024): Measures separability and agreement across tasks using metrics such as Brier scores for insights in specific domains such as coding, medical, finance, law and mathematics.
- CodeJudge-Eval (Zhao et al., 2024a): evaluates LLMs for judging code generation with execution-focused metrics such as accuracy and F1 score. This idea has also been adopted by several following works in code summarization and generation evaluation.
- Multimodal
- MLLM-as-a-judge (Chen et al., 2024a): extends evaluation frameworks to tasks involving multiple data modalities, focusing on agreement with human judgments, grading analysis, and hallucination detection.
- Multilingual
- MM-EVAL (Son et al., 2024b) and KUDGE (Son et al., 2024a): evaluate multilingual and non-English performance, measuring metrics like accuracy and correlation, particularly in challenging scenarios.
- Instruction Following
- Murugadoss et al. (2024): Examines the extent to which LLMs adhere to specific evaluation instructions using correlation metrics to quantify performance.
Challenges & Future Works
Bias & Vulnerability
Bias of using LLMs as judges can compromise fairness and reliability. These biases stem from the models’ training data, which often contain societal stereotypes and prejudices.
Specific biases that affect LLMs as judges:
- Order Bias: The sequence in which candidates are presented influences preferences.
- Egocentric Bias: LLMs favor outputs generated by the same model, compromising objectivity.
- Length Bias: Evaluations are skewed towards longer or shorter responses regardless of quality.
- Misinformation oversight bias: reflects a tendency to overlook factual errors.
- Authority bias: favors statements from perceived authoritative sources.
- Beauty bias: prioritizes visually appealing content over substantive quality.
- Verbosity Bias: Shows a preference for lengthier explanations, often equating verbosity with quality.
- Sentiment Bias: Favoring responses with positive phrasing
Vulnerability - LLM judges are also highly susceptible to adversarial manipulations.
- Carefully crafted adversarial sequences can manipulate LLM judgments to favor specific responses
- Universal adversarial phrases can drastically inflate scores in absolute scoring paradigms, revealing vulnerabilities in zero-shot assessment setups
To address these biases and vulnerabilities, frameworks like
- CALM (Ye et al., 2024a) and BWRS (Gao et al., 2024b) offer systematic approaches for bias quantification and mitigation.
- Multiple Evidence Calibration (MEC), Balanced Position Calibration (BPC), and Human-in-the-Loop Calibration (HITLC) have proven effective in aligning model judgments with human evaluations while reducing positional and other biases (Wang et al., 2023c).
- Cognitive bias benchmarks like COBBLER have identified six key biases, including salience bias and bandwagon effect, that need systematic mitigation in LLM evaluations
Future Direction:
- Integrating RAG Frameworks: Combining generative and retrieval capabilities to ground evaluations in external data sources can reduce biases, such as self-preference and factuality issues.
- Bias-Aware Datasets: Using datasets that explicitly address biases, e.g. OFFSETBIAS, in training can help LLMs distinguish superficial qualities from true quality.
- Fine-tuned LLMs as Judges: JudgeLM; Techniques like swap augmentation and reference support can improve consistency and mitigate biases.
- Zero-Shot Comparative Assessment Frameworks: (Liusie et al., 2023) Refining pairwise comparisons and implementing debiasing strategies can improve fairness without extensive fine-tuning.
- Security Enhancements: JudgeDeceiver-resistant calibration and adversarial phrase detection strategies need further exploration to secure LLM-as-a-judge frameworks from attacks
Dynamic & Complex Judgment
Early work on LLMs as judges relied on static prompting. However, to improve robustness and effectiveness, more dynamic and complex judgment pipelines are needed.
Promising directions:
- “LLM-as-an-Examiner”: Dynamically generating questions and judgments based on candidate performance (Yu et al., 2024b; Bai et al., 2023a)
- Debate-Based Frameworks: Assessing candidates based on multi-round debates and discussions. (Moniri et al., 2024; Zhao et al., 2024c)
- Complex Pipelines and Agents: Involving multi-agent collaboration, planning, and memory to handle diverse scenarios. (Li et al., 2023; Chan et al., 2023; Zhuge et al., 2024)
Future directions:
- Equipping LLMs with Human-like Judgment: borrow insights from human behavior when making a judgment, such as anchoring and comparing, hindsight and reflection, and meta-judgment.(Yuan et al., 2024a; Liang et al., 2024b)
- Adaptive Difficulty Assessment: Adjusting question difficulty based on candidate performance to create more accurate evaluations.
Self-Judging
- Egocentric Bias: LLMs tend to favor their own responses over those from other systems.
- Self-Enhancement Bias: LLMs overrate their outputs.
- Reward Hacking: Over-optimization leads to less generalizable evaluations.
- Static Reward Models: Limited adaptability in evaluation criteria.
- Positional and Verbosity Biases: Judgments are distorted by response order and length.
- Costly Human Annotations: Creating reliable evaluation systems is expensive.
Future research directions include:
- Collaborative Evaluation Frameworks like Peer Rank and Dis- cussion (PRD) (Li et al., 2023): Using multiple LLMs to evaluate outputs collectively, using weighted pairwise judgments and multi-turn dialogues to reduce self-enhancement bias and align evaluations closer to human stan- dards.
- Self-Taught Evaluator Frameworks: generate synthetic preference pairs and reasoning traces to iteratively refine model evaluation ca- pabilities. (Wang et al., 2024f) eliminates dependency on costly human annota- tions
- Self-Rewarding Language Models (SRLM): Employing mechanisms like Direct Preference Optimization (DPO) to improve instruction-following and reward-modeling capabilities, mitigating issues like reward hacking and overfitting.
- Meta-Rewarding Mechanisms: Introducing a meta-judge to evaluate and refine judgment quality, addressing biases like verbosity and positional bias. (Wu et al., 2024a)
- Synthetic Data Creation: Generating contrasting responses to train evaluators efficiently.
Human-LLM Co-judgement
Although limited research has been done on this approach, human involvement can help mitigate biases and improve LLM judgment.
Future directions include:
- LLMs as Sample Selectors: Using judge LLMs to choose a subset of samples for human evaluation based on specific criteria (e.g., representativeness or difficulty).
- Integrating Human-in-the-Loop Solutions: Learning from solutions in other fields, such as data annotation and active learning.
Reference:
- Li, Dawei, et al. “From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge.” arXiv preprint arXiv:2411.16594 (2024).