BLIP, a unified Vision-language Pre-training framework to learn from noisy image-text pairs. BLIP pre-trains a multimodal mixture of encoder-decoder model using a dataset bootstrapped from large-scale noisy image-text pairs by injecting diverse synthetic captions and removing noisy captions.
Challenges:
- Encoder-based models (CLIP, ALBEF) are less straightforward to transfer to text generation tasks (e.g. image captioning), whereas encoder-decoder models (SimVLM) have not been successfully adopted for image-text retrieval tasks.
- Noisy web text is suboptimal for vision-language learning.
Contributions:
Multimodal mixture of Encoder-Decoder (MED): a unified model with both understanding and generation capabilities.
Captioning and Filtering (CapFilt): dataset bootstrapping method for learning from noisy image-text pairs.
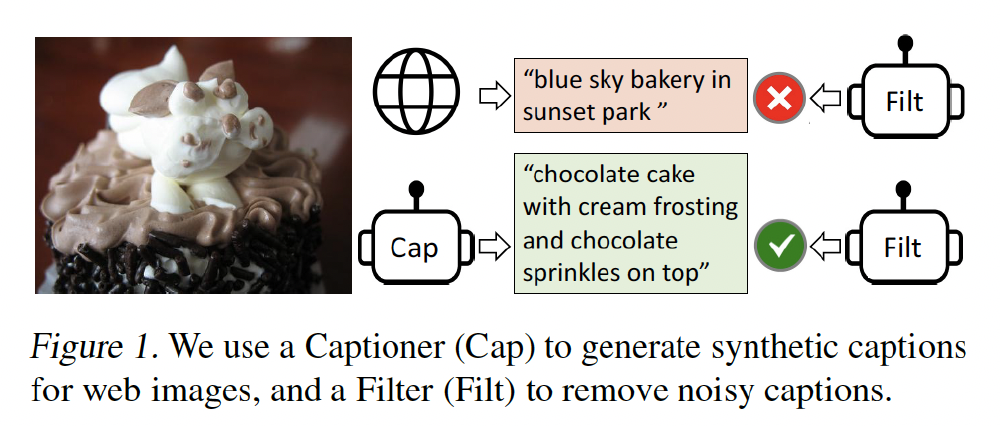
- a captioner: produce synthetic captions given web images
- a filter: remove noisy captions from both the original web texts and the synthetic texts.
Model Architecture: Multimodal mixture of encoder-decoder (MED)
- Unimodal encoder: separately encodes image(ViT) and text(BERT)
- Image-grounded text encoder: injects visual information by inserting one additional cross-attention (CA) layer between the self-attention (SA) layer and the feed forward network (FFN) for each transformer block of the text encoder.
- Image-grounded text decoder: replaces the bidirectional self-attention layers in the image-grounded text encoder with causal self-attention layers.
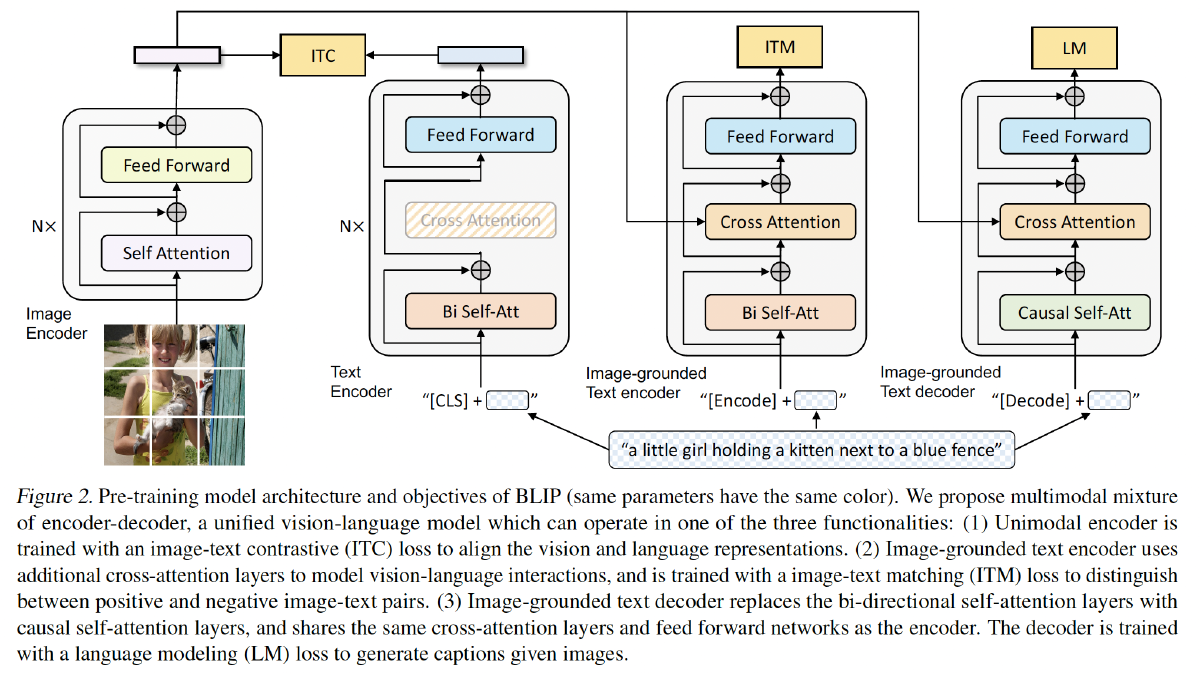
3 pre-training objectives:
- Image-Text Contrastive Loss (ITC): align the feature space of the visual transformer and the text transformer by encouraging positive image-text pairs to have similar representations. A momentum encoder is introduced for knowledge distillution.(V-I understanding)
- Image-Text Matching Loss (ITM): a binary classification task, where the model uses an ITM head (a linear layer) to predict whether an image-text pair is positive (matched) or negative (unmatched) given their multimodal feature. Adopt the hard negative mining strategy.
- Language Modeling Loss (LM): generate textual descriptions given an image. It optimizes a cross entropy loss which trains the model to maximize the likelihood of the text in an autoregressive manner.
The text encoder and text decoder share all parameters except for the SA layers, because,
- The encoder employs bi-directional self-attention to build representations for the current input tokens
- The decoder employs causal self-attention to predict next tokens.
CapFilt - improve the quality of the text corpus.
- The captioner is an image-grounded text decoder; finetuned with the LM objective to decode texts given images.
- The filter is an image-grounded text encoder; finetuned with the ITC and ITM objectives to learn whether a text matches an image.
Filtered image-text pairs + human-annotated pairs → a new dataset → pre-train a new model.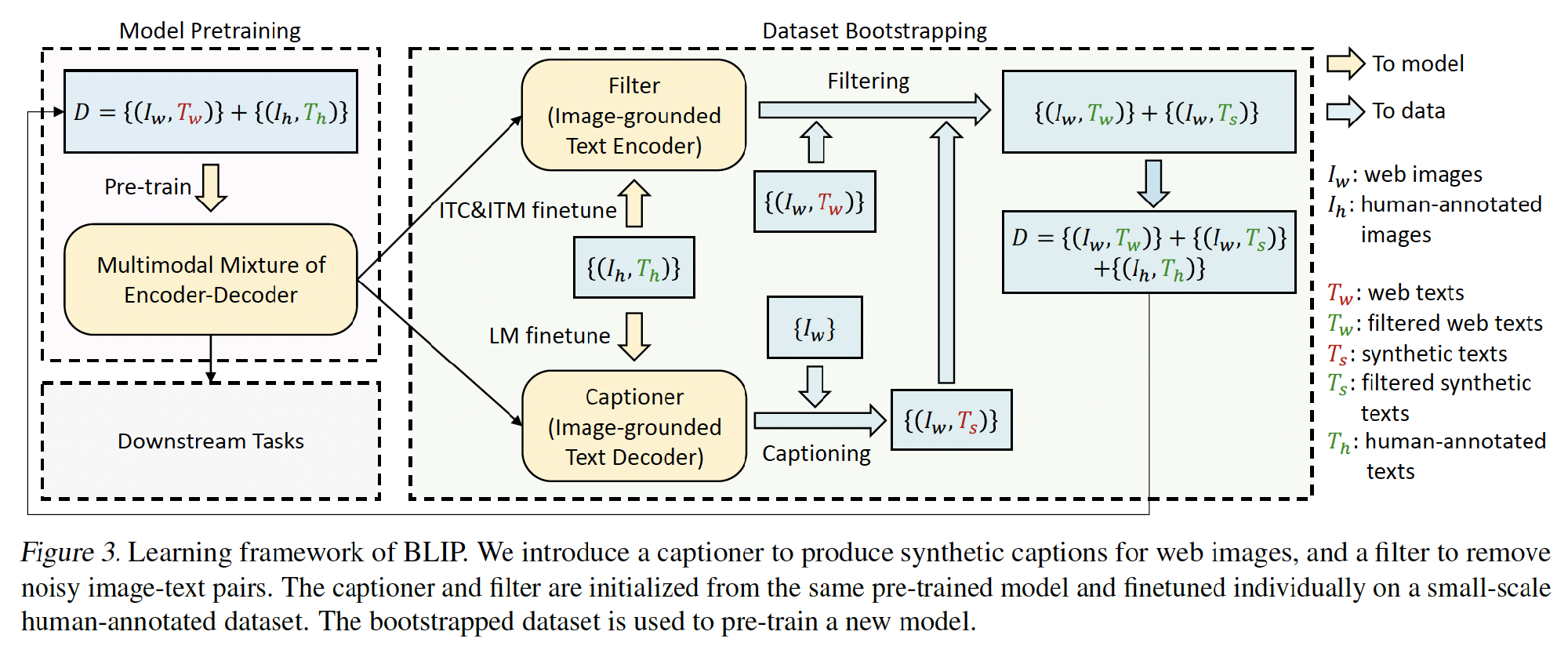
References: