Contribution:
- To enable more grounded vision and language representation learning, introduce a contrastive loss (from CLIP) to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which
- To improve learning from noisy web data, propose momentum distillation, a self-training method which learns from pseudo-targets produced by a momentum model.
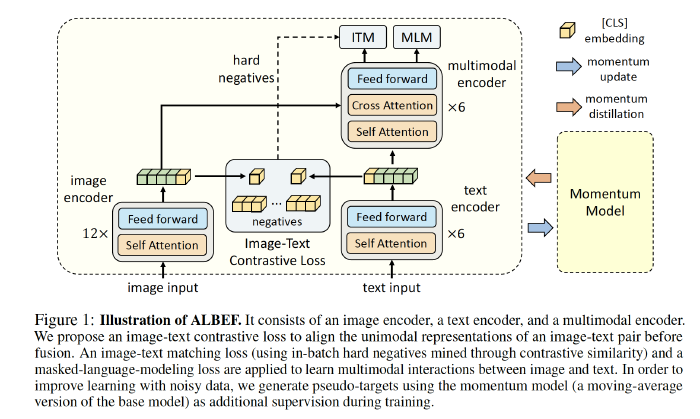
Model Architecture
ALBEF contains
- an image encoder: 12-layer visual transformer ViT-B/16
- a text encoder: first 6 layers of BERT
- An input image $I$ is encoded into a sequence of embeddings: ${v_{cls}, v_1,…,v_N}$
- a multimodal encoder: last 6 layers of BERT with additional cross-attention layers
- An input text $T$ is encoded into a sequence of embeddings: ${w_{cls}, w_1,…,w_N}$, which is fed to the multimodal encoder.
The image features are fused with the text features through cross attention at each layer of the multimodal encoder.
Pre-training Objectives
Pre-train ALBEF with three objectives:
image-text contrastive learning (ITC) on the unimodal encoders; Align
Aims to learn better unimodal representations before fusion.
It learns a similarity function $s = g_v(v_{cls})^\intercal g_w(w_{cls})$, such that parallel image-text pairs have higher similarity scores.
$g_v$ and $g_w$ are linear transformations that map the [CLS] embeddings to normalized lower-dimensional (256-d) representations. (downsampling/normalization)
The normalized features from the momentum encoders are denoted as $g^{’}v(v^{’}{cls})$ and $g^{’}w(w^{’}{cls})$ . We define $s(I,T) = g_v(v_{cls})^\intercal g^{’}w(w^{’}{cls})$, and $s(T,I) = g_w(w_{cls})^\intercal g^{’}v(v^{’}{cls})$.
For each image and text, we calculate the softmax-normalized image-to-text and text-to-image similarity as:
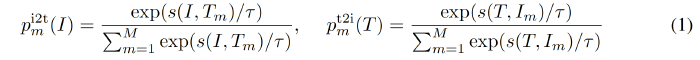
The image-text contrastive loss is defined as the cross-entropy $H$ between $\mathbf{p}$ and $\mathbf{y}$:
- $y^{i2t}(I)$ and $y^{t2i}(T)$ denote the ground-truth one-hot similarity, where negative pairs have a probability of 0 and the positive pair has a probability of 1.
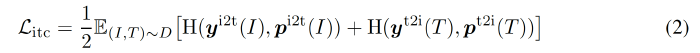
masked language modeling (MLM) on the multimodal encoder.
Randomly mask out the input tokens with a probability of 15% and replace them with the special token [MASK]; utilizes both the image and the contextual text to predict the masked words.
MLM minimizes a cross-entropy loss:
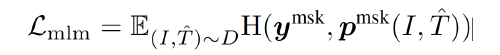
- $\hat{T}$ : a masked text
- $\mathbf{p}^{msk}(I, \hat{T})$ : the model’s predicted probability for a masked token.
- $\mathbf{y}^{msk}$: one-hot vocabulary distribution where the ground-truth token has a probability of 1.
image-text matching (ITM) on the multimodal encoder.
Predicts whether a pair of image and text is positive (matched) or negative (not matched).
We use the multimodal encoder’s output embedding of the [CLS] token as the joint representation of the image-text pair, and append a fully-connected (FC) layer followed by softmax to predict a two-class probability $p^{itm}$.
The ITM loss:
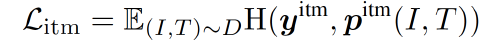
- $\mathbf{y}^{itm}$: 2-dimensional one-hot vector representing the ground-truth label.
Propose contrastive hard negative mining which selects informative negatives with higher contrastive similarity.
The full pre-training objective of ALBEF is:
$$ L = L_{itc} + L_{mlm} + L_{itm} $$
Momentum Distillation
Challenge: web data noisy.
- Negative texts for an image may also match the image’s content (ITC);
- There may exist other words different from the annotation that describes the image equally well (MLM).
However, the one-hot labels for ITC and MLM penalize all negative predictions regardless of their correctness.
Solution: learn from pseudo-targets generated by the **momentum model (**exponential-moving-average versions of the unimodal and multimodal encoders).
During training, we train the base model such that its predictions match the ones from the momentum model.
$ITC_{MoD}$ loss:
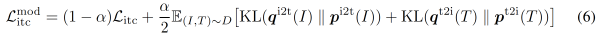
$MLM_{MoD}$ loss:
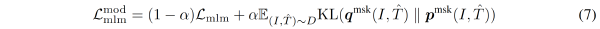
- $q^{msk}(I,\hat{T})$ denote the momentum model’s prediction probability for the 8masked token
So actually Albef has 5 loss functions: 2 $L_{itc}$, 2 $L_{mlm}$, 1 $L_{itm}$

Downstream V+L Tasks
Image-Text Retrieval : image-to-text retrieval (TR) and text-to-image retrieval(IR).
Visual Entailment: predict whether the relationship between an image and a text is entailment, neutral, or contradictory; consider VE as a three-way classification problem.
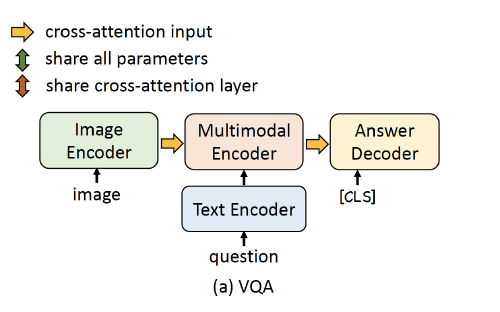
Visual Question Answering:
use a 6-layer transformer decoder to generate the answer.
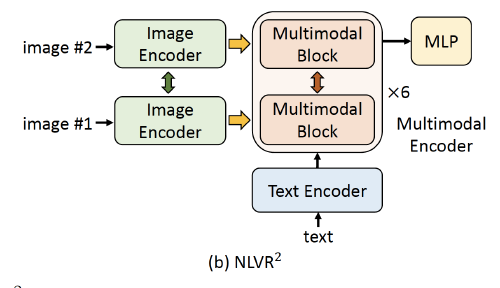
Natural Language for Visual Reasoning: predict whether a text describes a pair of images.
Visual Grounding: localize the region in an image that corresponds to a specific textual description.
Reference: