With the explosion of Large Language Models (LLMs), there is a growing demand for researchers to train these models on downstream tasks. However, training LLMs often requires a great amount of computing resources, making them inaccessible to many individual researchers and organizations. In response, several advancements in Parameter-Efficient Fine-Tuning (PEFT) have emerged. The idea of PEFT techniques is to fine-tune a much smaller number of the model parameters while maintaining the model performance, thus allowing researchers to train large models more efficiently and cost-effectively. These methods have gained significant traction across various applications, which makes broader experimentation and deployment of LLMs in real-world scenarios possible.
Among many of the PEFT methods, Low-Rank Adaptation (LoRA) is a quite common way to efficiently train LLMs by leveraging low-rank factorization. In the following paragraphs, we will overview LoRA and some key LoRA variants.
LoRA
Low-Rank Adaptation (LoRA) reduces the number of trainable parameters in large pre-trained language models like GPT-3, making it more efficient and cost-effective for specific tasks without sacrificing performance. Unlike traditional fine-tuning that requires adjusting the entire model, LoRA works by freezing the pretrained model weights and injecting two smaller, trainable rank decomposition matrices A and B into each layer of the Transformer architecture, thereby reducing computational and memory overhead (Figure 1).
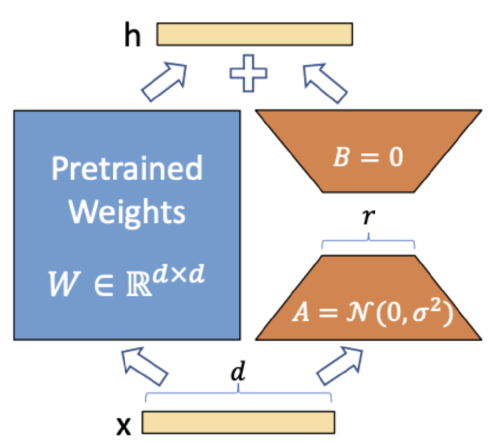
During training, we only train lower-rank matrices, which change faster than full-finetuning because of fewer parameters. During inference, we add the weights of lower-rank matrices to the pre-trained weights. In general, wetrain a much smaller number of parameters on top of a large model and add their output to the original model weights, which influences the behavior of the model.
LoRA Variants
AdaLoRA
Adaptive Low-Rank Adaptation (AdaLoRA) builds on the standard LoRA approach by dynamically allocating parameter budgets to weight matrices based on importance scores during LoRA-alike fine-tuning.
The motivation is that the weight matrices in different layers are not equally important, adding more trainable parameters to the critical weight matrices can lead to better model performance. Compared to LoRA, which distributes parameters evenly across all layers, AdaLoRA assigns higher rank to critical incremental matrices. This assignment forces injected matrices to capture more fine-grained and task-specific information. AdaLoRA also prunes less importance matrices to have lower rank to prevent overfitting and save the computational budget.
Overfitting is prevented by parameterizing the incremental updates of the pre-trained weight matrices in the form of singular value decomposition (SVD). An additional penalty is added to the training loss to regularize the orthogonality of the singular matrices, thereby avoiding extensive SVD computation and stabilizing the training. 
QLoRA
Quantized Low-Rank Adaptation (QLoRA) optimizes the standard LoRA approach by introducing quantization to reduce memory usage enough to finetune LLM model like ChatGPT on a single GPU while preserving full finetuning task performance. This marks a significant shift in accessibility of LLM finetuning. There are 3 key innovations:
4-bit NormalFloat (NF4), an information theoretically optimal quantization data type for normally distributed data that yields better empirical results than 4-bit Integers and 4-bit Floats.
Double Quantization, a method that quantizes the quantization constants, saving an average of about 0.37 bits per parameter (approximately 3 GB for a 65B model).
Paged Optimizers, using NVIDIA unified memory feature which does automatic page-to-page transfers between the CPU and GPU to avoid the gradient checkpointing memory spikes. The memory spikes sometimes cause GPU out-of-memory errors that have traditionally made finetuning on a single machine difficult for large models.
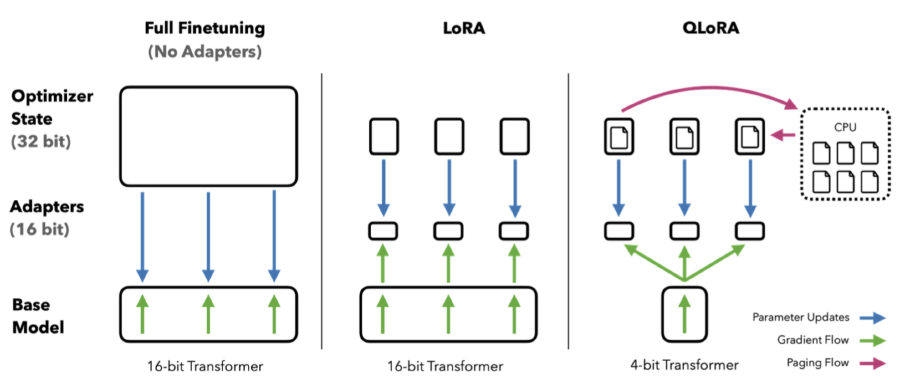
Figure 2: Different finetuning methods and their memory requirements.
DoRA
Weight-Decomposed Low-Rank Adaptation (DoRA) improves on the standard LoRA approach by decomposing the pre-trained weight into its magnitude and directional components, then fine-tunes both. It outperforms LoRA on various NLP, multi-modal tasks without any additional inference latency.
It starts with a weight decomposition analysis, which restructures the weight matrix into magnitude and direction, examines the updates in both magnitude and direction of the LoRA and full finetuning weights relative to the pre-trained weights, and reveals there are fundamental differences in the learning patterns of LoRA and full finetuning.
Then, based on these learnings, it introduces DoRA, which is initialized by pre-trained weights, decomposes it into its magnitude and directional components and finetunes both of them. The directional component is further decomposed with LoRA as its size is proportional to the parameter size of pre-trained weight. A schematic representation of this process is shown in Figure 3.
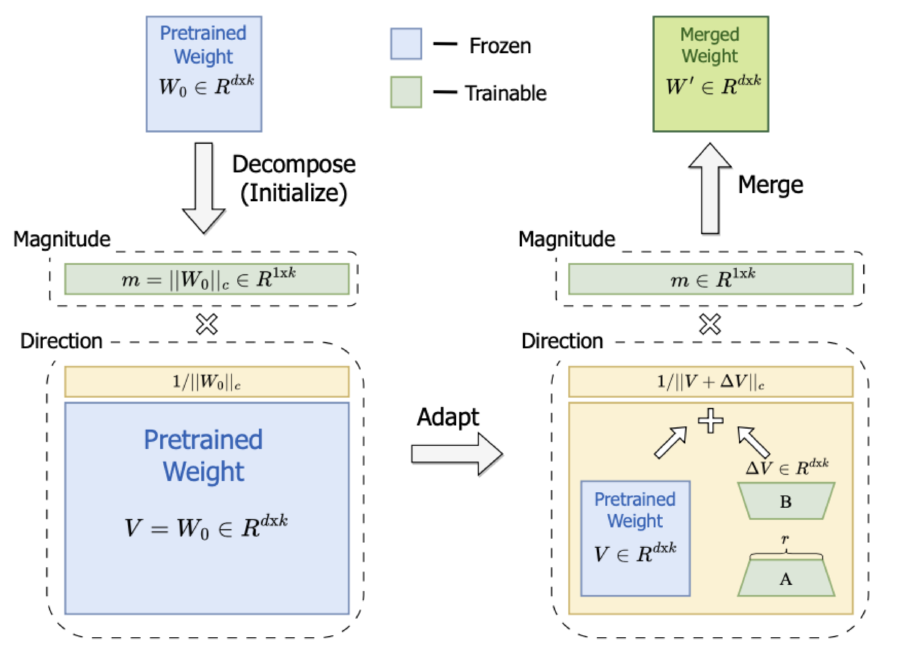
Figure 3: An overview of DoRA method
Summary
In this blog post, we reviewed the LoRA method and several of its variants. The innovations introduced by LoRA, AdaLoRA, QLoRA, DoRA, and other LoRA-based methods represent significant advancements in the field of Parameter-Efficient Fine-Tuning (PEFT) for large language models (LLMs). By Lleveraging techniques such as dynamic parameter allocation, quantization, and weight decomposition, these methods makes it feasible for researchers with limited computing resources to train and fine-tune large models effectively. As the demand for fine-tuning large models continues to grow, the LoRA family provides a promising approach to democratizing access to powerful AI tools.
References
Hu, Edward J., et al. “Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021).
Zhang, Qingru, et al. “AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning.” arXiv preprint arXiv:2303.10512 (2023).
Dettmers, Tim, et al. “Qlora: Efficient finetuning of quantized llms.” Advances in Neural Information Processing Systems 36 (2024).
Liu, Shih-Yang, et al. “Dora: Weight-decomposed low-rank adaptation.” arXiv preprint arXiv:2402.09353 (2024).
https://huggingface.co/docs/peft/en/developer_guides/quantization