RDD(Resilient Distributed Dataset): a core abstraction enabling both an efficient execution for a computation, and a flexible and convenient formalism to define computations.
Resilient — able to withstand failures
Distributed — spanning across multiple machines
Formally, RDD is a read-only, partitioned collection of records
To say that the dataset is an RDD, the dataset must adhere to the RDD interface.
The dataset must be:
able to enumerate its partitions by implementing the partition’s function.
partitions() -> Array[Partition]
The partition is an opaque object for the framework. It is passed back to the iterator function of the RDD, when the framework needs to read the data from the partition.
relation between consequent steps is known only to the user code not the framework
framework has no capabilities to optimize the whole computation
framework must reliably persist data between steps thus generating excessive I/O (even if it is temporary data)
In this scenario,Spark is trying to keep the data in the memory, effectively eliminates an intermediate disk persistence, and thus improving the completion time.
Example: joins
join operation is used in many MapReduce applications
Implement the necessary functions to make the binary file in RDD
To implement the partition’s function: lookup the blocks for NameNode, create a partition for every block, and return the partitions.
To implement the iterator’s function: extract the block information from the partition, and use it to create a reader from HDFS.
To implement the dependencies’ function: File reading does not depend on any other RDD, nor on any other partition. So implementing the dependencies function is trivial. It returns an empty array
The simplest way to make the array in RDD is to pretend that there is a single partition with the whole array. In this case, the partition object keeps a reference to the array, and the iterator function uses this reference to create an iterator.
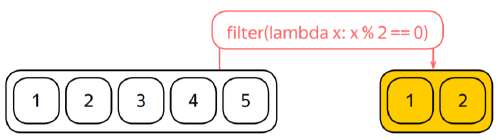
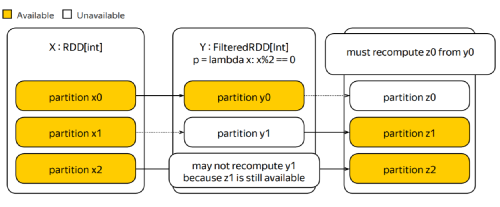
returns a filtered RDD with items satisfying the predicate p
Filtered RDD:
partitions: transformed RDD’s mostly the same as source one–>reuse partitions of the source RDD as there is no need to change the partitioning.
dependencies: every field of partition depends on the source partition. You can establish this relation by providing a dependency object that establishes one-to-one correspondence between the filtered and the source partitions.
iterator: when creating an iterator over the filter partition:
Spark would inject an iterator of the source partition into the iterator function called
reusing the parent iterator.
When requested for the next value, you can pull values from the parent iterator until it returns you an item that satisfies the predicate.
Actual filtering happens not at the creation time of Y, but at the access time to the iterator over a partition of Y.The filtering starts to happen only when you start to pull items from the iterator.
Same holds for other transformations – they are lazy,i.e. they compute the result only when accessed.
collect action collects the result into the memory of the driver program.
intended to be used when the output is small enough to fit into the driver’s memory.
take action takes the given number of items from a data set and passes them back to the driver.
tries to use only the first partition of a data set to optimize the completion time.When the result is large enough, you may want to save it to HDFS for example. Doing so by collecting items in the driver will quickly run out of memory.
There are special family of safe actions that do heavy work on the executor side and return a confirmation to the driver.
SaveAsText file is used for full debugging or for simple applications
SaveAsHadoopFile leverages Hadoop file formats to serialize data–>common way to save data to HDFS.
If you need to run your own code over a data set, there are foreach and foreachPartition actions that invoke your function on the executor side.
You can use this function to persist your data in your custom database for example, or to send data over the wire to an external service, or anything else.
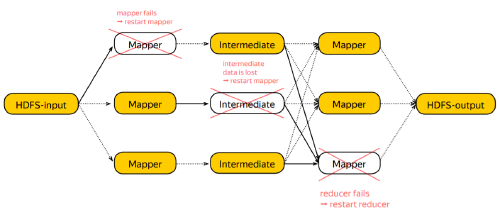
Lineage — a dependency graph for all partitions of all RDDs involved in a
computation up to the data source
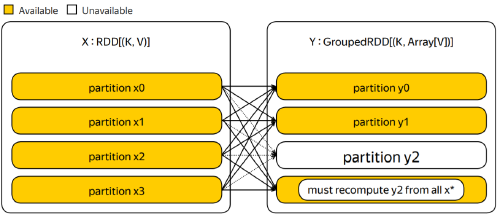
Machine failure renders some partitions in the lineage unavailable. To cope with the failure, you must detect which partitions become unavailable, and decide what to restart.
Detection is done in the Driver Program, because the Driver Program orchestrates the execution, and already tracks the partitions.
Deciding what to restart: Given the failed partition, you look at its dependencies, and if they are alive, restart the computation. If the dependencies are failed as well, you recursively try to recover them.
Restarts are slightly more fragile in the case of wide dependencies, because to recompute an output partition, all dependencies must be alive, and there are many of them. If dependencies you evicted out of a cache for example, the restart will be expensive.
Actions are side-effects in Spark (communicate with external services)
Actions have to be idempotent幂等(自己重複運算的結果等於它自己的元素) that is safe to be re-executed multiple times given the same input
Example: collect()
all transformations are deterministic, the final data set isn’t changed in case of restarts. Therefore, even if the collect action fails, it could be safely re-executed
Example: saveAsTextFile()
since the data set is the same, you can safely override the output file
assuming deterministic & side-effect free execution of transformations(including closures)
all the closures pass to Spark, must be deterministic and side effect free
assuming idempotency for actions
These properties cannot be checked or enforced at the compile time, and may lead to obscure bugs in your application that are hard to debug and hard to reproduce.