Study note of Big Data Essentials: HDFS, MapReduce and Spark RDD
Execution & Scheduling
SparkContext
- When creating a Spark application, the first thing you do is create a SparkContext object, which tells Sparks how to access a cluster.
- The context, living in your driver program, coordinates sets of processes on the cluster to run your application.
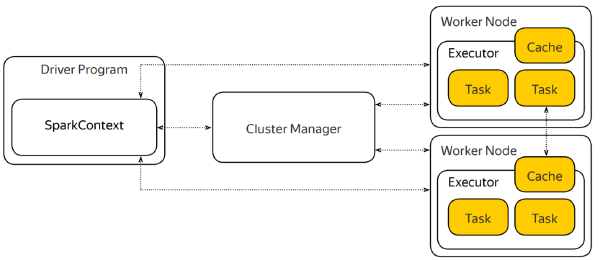
- The SparkContext object communicates the Cluster Manager to allocate executors.
- The Cluster Manager is an external service for acquiring resources on a cluster. For example, YARN, Mesos or a standalone Spark cluster.
- once the context has allocated the executors, it communicates directly with them and schedules tasks to be done.
Jobs, stages, tasks
- Task is a unit of work to be done
- Tasks are created by a job scheduler during the scheduling of a job for every job stage. And every task belongs to the job stage.
- Job is spawned in response to a Spark action
- Job is divided in smaller sets of tasks called stages
Example
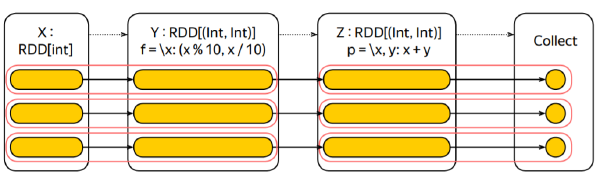
Z = X .map(lambda x: (x % 10, x / 10)) .reduceByKey(lambda x, y: x + y) .collect()
Whenever you invoke an action, the job gets spawned in the driver program.

Then the driver runs a job scheduler to divide the job into smaller stages.
Then tasks are created for every job stage.
tasks are delegated to the executors, which perform the actual work.
bash
All this machinery exists within the SparkContext object. It keeps track of the executors, it spawns jobs, and it runs the scheduler.
Difference between job stage and task:
- Job stage is a pipelined computation spanning between materialization boundaries
- job stages are defined on RDD level, thus not immediately executable
- Task is a job stage bound to particular partitions
- bound to a particular partitions, thus immediately executable
- Materialization happens when reading, shuffling or passing data to an action
- narrow dependencies allow pipelining
- wide dependencies forbid it
SparkContext – other functions:
- Tracks liveness of the executors by sending heartbeat messages periodically.
- required to provide fault-tolerance
- Schedules multiple concurrent jobs
- to control the resource allocation within the application
- Performs dynamic resource allocation if the cluster manager permits.
- increases cluster utilization in shared environments by proper scheduling of multiple applications according to their resource demands
Summary
- The SparkContext is the core of your application
- allows your application to connect to a cluster and allocate resources and executors.
- whenever you invoke an action, the SparkContext spawns a job and runs the job scheduler to divide it into stages–>pipelineable
- tasks are created for every job stage and scheduled to the executors.
- The driver communicates directly with the executors
- Execution goes as follows:
Action -> Job -> Job Stages -> Tasks
- Transformations with narrow dependencies allow pipelining
Caching & Persistence
- RDDs are partitioned
- Execution is build around the partitions
- Each task processes a small number of partitions at a time, and the shuffle globally redistributes data items between the partitions, when required.
- Spark transfers data over the network and the IO unit here is not a partition but a block.
- Block is a unit of input and output in Spark
Example
Motivating example: load a wikipedia dump from HDFS and see how many articles there contain the words Spark
You need to create the RDD, apply the filter transformation, and invoke the count action.
Motivating example: among those articles with the Spark word, you would like to see how many of them contain the word, Hadoop and how many the word MapReduce.

Perform worse!
Reason: after completing the computation, Spark disposes intermediate data and those intermediate RDDs. That means, it will reload the Wikipedia dump two more times incurring extra input and output operations.
A better strategy:
cache the preloaded dump in the memory and reuse it until you end your session.
Spark allows you to hint which RDDs are better to be kept in memory or even on the disk. Spark does so by ***caching the blocks comprising your dataset. ***
Controlling persistence level
Cache: mark the data set as cached by invoking a cache method on it
- The cache method is just a shortcut for the memory-only persistence.
Persist: allows you to set RDDs storage to persist across operations after the first time it is computed.
- parameterized by a storage level

Best practices
When running an interactive shell, cache your dataset after you’ve done all the necessary preprocessing.
- by keeping your work inside in the memory, you would get a more responsive experience.
When running a batch computation, cache dictionaries that you join with your data.
- Join dictionaries are often reshuffled, so it would be helpful to speed up their read times.
When running an iterative computation, cache static data like dictionaries or input datasets
- avoid reloading the data from the ground up on every iteration.
- The static data tends to get evicted due to the memory pressure from the intermediate data.
Summary
- Performance may be improved by persisting data across operations
- in interactive sessions, iterative computations and hot datasets
- You can control the persistence of a dataset
- whether to store in the memory or on the disk
- how many replicas to create
Broadcast Variable
shared memory is a powerful abstraction, but often misused.
- It can make the developer’s life easier
- It can make the application performance deteriorate because of extra synchronization.
This is why in spark there are restricted forms of the shared memory.
Broadcast variable is a read-only variable that is efficiently shared among tasks
one to many communication: When it captures a variable into the closure, it is sent to an executor together with a task specification.
many to many communication protocol: torrent
- Distribution is done by a torrent-like protocol (extremely fast!)
- Distributed efficiently compared to captured variables
Example
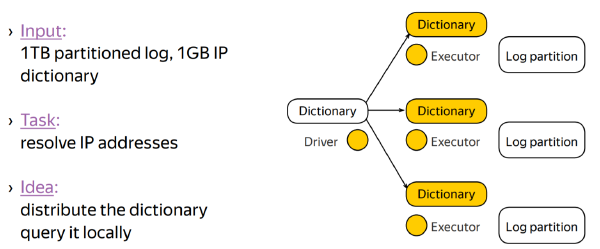
Motivating example: resolve IP addresses to countries from 1 terabyte access log for your website
Idea: map-side join–distribute the database to every mapper and query it locally.
Distributing the database via a broadcast variable, we take slightly more than 1 gigabyte of outgoing traffic at the driver node
Motivating example:
- setup a transformation graph to compute a dictionary
- invoke the collect action to load it into the driver’s memory
- put it into the broadcast variable to use in further computations.
Idea: upload computations to spark executors and use the driver program as the coordinator.
Summary
- Broadcast variables are read-only shared variables with effective sharing mechanism
- Useful to share dictionaries, models
Accumulator Variable
Accumulator variable is a read-write variable that is shared among tasks
- Writes are restricted to increments!
- i. e.: var += delta
- addition may be replaced by any associate, commutative operation
Restricting the right operations allows the framework to avoid complex synchronization thus making the accumulators efficient.
- Accumulator variable could be read only by the driver program and not by the executors.
- cannot read the accumulated value from within a task
Example
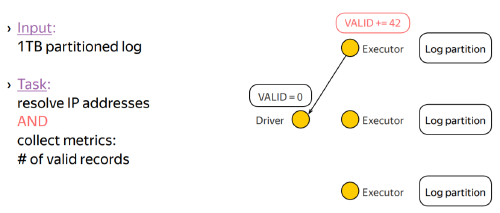
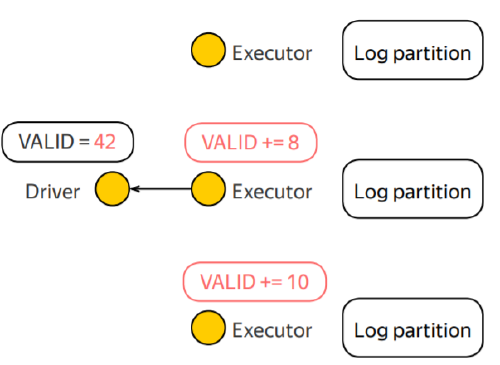
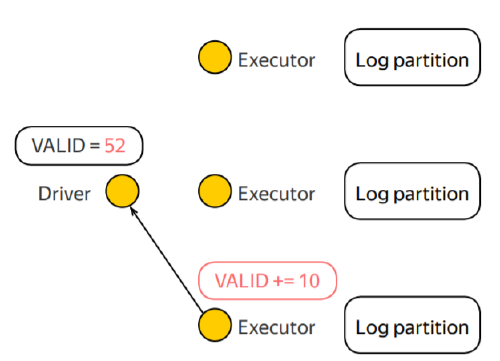
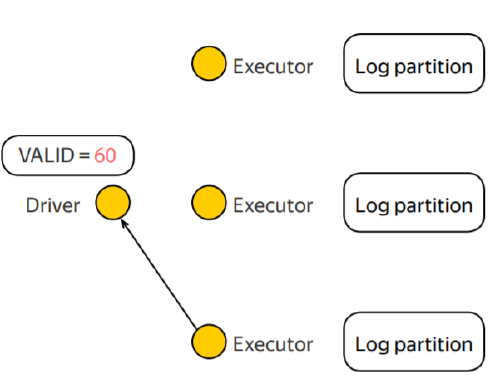
Guarantees on the updates
- Updates generated in actions: guaranteed to be applied only once to the accumulator.
- This is because successful actions are never re-executed and Spark can conditionally apply the update.
- Updates generated in transformations: no guarantees when they accumulate updates. - - Transformations can be recomputed on a failure, on the memory pressure, or in another unspecified codes like a preemption.
- Spark provides no guarantees on how many times transformation code maybe re-executed.
Use cases
- Performance counters
- number of processed records, total elapsed time, total error and so on and so forth
- Simple control flow
- conditionals: stop on reaching a threshold for corrupted records
- loops: decide whether to run the next iteration of an algorithm or not
- Monitoring
- export values to the monitoring system
- Profiling & debugging
Summary
- Accumulators are shared read-write variables with de-coupled read and write sides
- could be updated from actions and transformations by using an increment.
- can use custom associative, commutative operation for the updates
- can read the total value only in the driver
- Useful for the control flow, monitoring, profiling & debugging